(Originally posted on bughousesquare.wordpress.com)
Over the past year or so I’ve been working on digital history project that aims to convert a 1925 American Labor Who’s Who into a research and teaching database and wiki. It continues to be “a learning experience,” as my mother used to call all the unpleasant encounters of childhood. Not all bad, to be sure, but not all good. Since I have versions of the data up on the internet, I thought I should post some reflections.
Labor historian Jon Beck from the Michigan State Industrial Relations program started my thinking about the Labor’s Who Who around 2007 or so when he suggested it might be useful for my project on working class autodidacts. The Rand School of Social Science sponsored the compilation of the Who’s Who in 1925 under the direction of Solon De Leon (son of famed radical Daniel De Leon). De Leon and his colleagues threw open the front door to the House of Labor, so to speak, including in the roughly 1,300 entries for the U.S. activists in the fields of immigrant rights, civil liberties, cooperatives, progressive and radical politics, as well as the to-be-expected trade unionists (there are 300 additional non-US activists–a few of these were deported or self-exiled US activists).
Nineteen twenty-five was a curious moment for the American labor movement. The industrial union upsurge of the 1910s was sputtering under the weight of repression, factionalism, and failure. The powerful unions of the CIO were a decade or more in the future. Meanwhile, conservatives held a tight, if a bit desperate, grip on the political machinery of trade unionism at the national level, antiunion Republicans were in the White House, and reactionary groups like the KKK and American Legion were popular. And yet, there was a great deal of activity and organizational creativity in some unions, and there was a blossoming network labor colleges training the leaders of the ’30s.
The Labor Who’s Who is a snapshot of this contingent moment and some of the people who lived it. Each entry is a telegraphic biography. Some provide only name, professional title and address at the time of publication. But many sketch rich life histories. Nearly all provide details on birth date and place, family background, education, migration, and work histories, as well as key organizations, events and publications. It includes both long-serving elders whose careers stretched back to the 1870s, and emerging leaders who would continue to be active into the second half of the 20th century.
For years I had a library copy of the book on my office shelf, thinking I would get to the project eventually. Then in 2012 I discovered the book had been scanned by Google and was sitting behind the access wall in the HathiTrust (HT) digital collection. You could search keywords, but the search only returned a few words and a page number. From my key word searches, I knew that about 40 individuals identified themselves as “self-educated,” but learning more about the educational and organization matrix represented in the directory was just beyond reach. Hoping to avoid the wrath of Disney and other commercial publishers, HT takes a defensive approach to copyright. Most things published after the easy cut off for public domain (before 1923) go behind the access wall.
Very frustrating. And ironic. Here was a book published by a radical college, locked behind a copyright wall at the behest of capitalist media corporations. Not that these corporations give a hoot about the Labor Who’s Who, it’s just structural. Everything after 1922 goes behind the wall unless someone specifically requests it be freed.
Thus was born what I’m now calling the “HathiTrust Liberation Project.” Hundreds and hundreds of labor and leftist volumes published between 1923 and 1963 are in the public domain unless their copyright holders renewed the copyright (there is an online database of to check for renewed copyrights: http://comminfo.rutgers.edu/~lesk/copyrenew.html ). Unlike literary works, mundane works of non-fiction and social movement publications are usually not renewed. Many of these volumes are already digitized, but are blocked. Likewise, a surprising number of post-1923 government documents are behind the access wall.
The Labor Who’s Who was my first foray into old book liberation. Through the good graces of the UCLA Library, I was able to convince HT that the copyright on the Labor Who’s Who probably wasn’t renewed, and in any case the socialists won’t kick if you open it up. Somebody flipped a switch and the volume appeared. This was in the spring or summer of 2012.
The next task was extracting and cleaning OCR’d text. This turned out to be a little more complicated than I expected. In the end, I downloaded an EPUB version of the Who’s Who, and copy-and-pasted the text into a separate file. So far, so good. But this was a long way from a database. With the help of UCLA librarian Zoe Borovsky and Miriam Posner of the Center for Digital Humanities, I got some help breaking the text up into discreet entries and, eventually, data fields. However, there were many, many text recognition errors. I probably could have hired someone to do it (if I had the money), but in the end I did most of the corrections myself. Let’s just say I became intimately familiar with the contents of the book. And isn’t that the traditional activity of scholarly humanists after all, even if this mode of familiarity generally is not recognized as such by personnel committees.
So by the late fall of 2012, I had a relatively clean text file with entries broken into fields: name, titles, birthplace, birth date, father’s occupation, and a residual field that was too irregular to easily parse that included things like education, organizations, activities, publications, home and work address. Next came the task of reorganizing this information from a flow of text into a spreadsheet, rather tediously done by cutting and pasting in Microsoft Excel.
From the start, I had envisioned the Who’s Who database as a teaching tool, as well as a research project. I imagined students using the entries as a starting place for biographical papers, so I needed a student-friendly interface. I had experimented fitfully having students write or edit Wikipedia entries in my classes, so it seemed natural to put the Who’s Who data in a wiki. A regular wiki is searchable, but doesn’t really have database functions. To get those, I used the Mediawiki extension bundle Semantic Mediawiki. The semantic wiki allows you to define data fields and relationships, import data, search across data fields, and enable students or other users (if you wish) to edit the data through forms.

 I also loaded the data into a Google Fusion Table, which allows you to quickly make maps from any geographic data (e.g., birthplaces). Fusion Tables is easy, but limited in terms of customizing. My students used the filtering and mapping functions to produce in-class reports on the demographics of various organizations represented in the directory. Semantic Mediawiki is much more flexible. But for the non-expert it was one of those “learning experiences.” Many late nights, crashes, and frustrations before ultimate success. In the future I hope to use it in my labor history classes to train students how to use a wiki before I set them off on the actual Wikipedia.
I also loaded the data into a Google Fusion Table, which allows you to quickly make maps from any geographic data (e.g., birthplaces). Fusion Tables is easy, but limited in terms of customizing. My students used the filtering and mapping functions to produce in-class reports on the demographics of various organizations represented in the directory. Semantic Mediawiki is much more flexible. But for the non-expert it was one of those “learning experiences.” Many late nights, crashes, and frustrations before ultimate success. In the future I hope to use it in my labor history classes to train students how to use a wiki before I set them off on the actual Wikipedia.
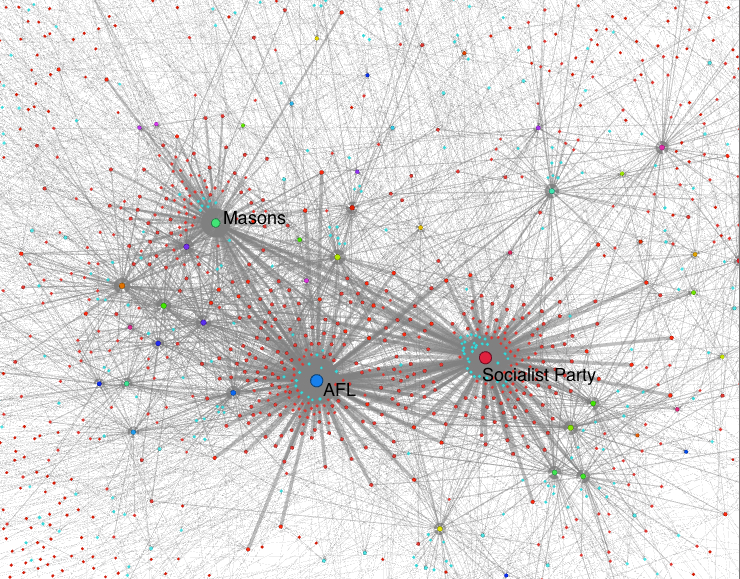
What remains to be done is the “Other” field–education, organizations, publications–lots of good stuff. I’m currently working with folks at the Center for Digital Humanities, and hope to have that done by late winter. In the meanwhile, I’m doing some analysis of subsets of the Who’s Who, particularly the organizational networks. And that presents me with my next “learning experience,” Gephi.