This is the fourth a series of posts I am writing to help me think through the use of network analysis and visualization.
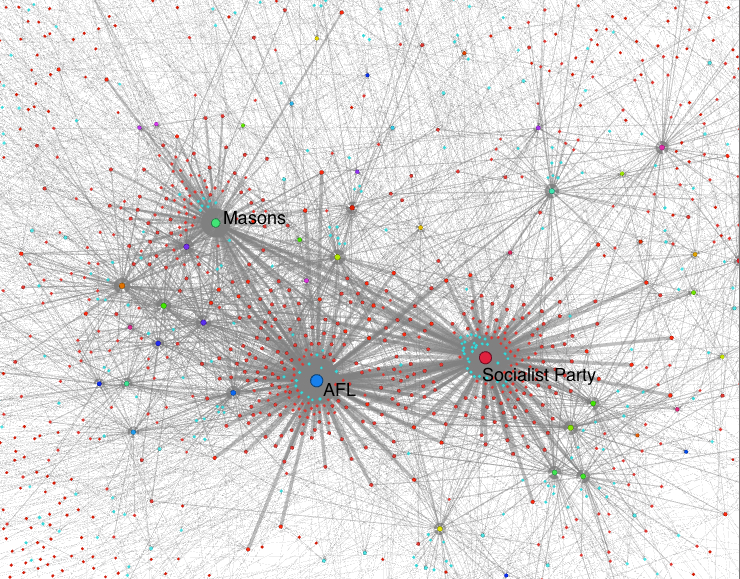
About seven months ago, I was merrily chugging along on this series using the index of the 1925 American Labor Who’s Who as a database for network analysis when I hit an impasse. I was using the list of names and organizations from the book’s index to build network charts. However, the simple structure of the index, so handy for the analog book, adds a layer of abstraction/interpretation that gets in the way of analysis.
The Labor Who’s Who index presents names according to two types of categories. The first might be called “varieties of organization” and includes American Federation of Labor Affiliated Bodies, Independent Unions, Political Parties, and Miscellaneous. Of these, only “AFL-affiliated” is an organic category. “Political Parties,” on the other hand, is a conceptual category, not an entity that the Socialist Party or the Republican Party affiliated with. At the next level down things get more complicated. Things get even messier in the Miscellaneous category, which includes Journalists and Writers, Negro Progress, Workers Education, and a few others. Unfortunately, the index doesn’t tell us the particular newspapers and organizations that make up these sub-groupings in Miscellaneous.
Neither does the index list all the organizational affiliations listed in individual entries, it is more of a snapshot of what the compilers thought were the most important memberships of each person. The result is a simplified, and perhaps, distorted image of the network of associations, and my research impasse. I was at the point of pulling out particular sections of the network chart (those individuals who sat between the two main groupings), but it seemed better to stop and develop the full database than continue with the index alone.
Easier said than done. The complete directory of over 1,000 names is much messier than the index (see the post “Old Book, New Data”). In addition to basic OCR scanning errors there are a few missing and torn pages in the scanned version. The enormity of the task of cleaning the data myself loomed. One solution was to “crowd source” the data cleaning, but that might take a long time and who would really be interested? Another potential solution was to deploy undergraduate students as a “curated crowd.” Because I was already scheduled to teach an upper division lecture course on American Working Class Movements in the fall of 2014, I developed a course project that included a small amount of data cleaning for students–and (as it turned out) a lot of help from two graduate students in the UCLA Center for Digital Humanities. I’ll write about what went right and wrong with that process in a later post, but the upshot is that now I have a working version of the complete directory.
And with that news, I will begin to post more regularly over the next month.